Some thoughts on GitHub Copilot - Your AI pair programmer
Today marked the technical preview of GitHub Copilot - Your AI pair programmer. It’s something I’ve long been expecting ever since Microsoft acquired GitHub for $7.5 billion.
When the news first broke about GitHub and Microsoft, it wasn’t intuitively obvious outside of developer circles why Microsoft chose the deal. It was clear to developers by purchasing GitHub that Microsoft now had access to the worlds largest repository of code on the planet. How Microsoft was going to use this new shiney dataset worried a lot of people.
Microsoft has always been a tools company, operating systems and spreadsheets being their money maker for decades. GitHub has allowed Microsoft to take prime place in the toolkit for the modern developer, slowly introducing features that integrate closer and closer with Microsofts offerings. GitHub actions integrate directly with their cloud offering Azure. Copilot has brought Visual Studio Code to the fore becoming the only IDE with a direct extension available to integrate with this new model.
GitHub partnered with OpenAI to build Copilot. OpenAI published GPT-3, the largest language model ever trained. GPT-3 has 175 billion parameters and would require 355 years and $4,600,000 to train. Copilot is the next iteration of GPT-3 focused on code rather than natural language.
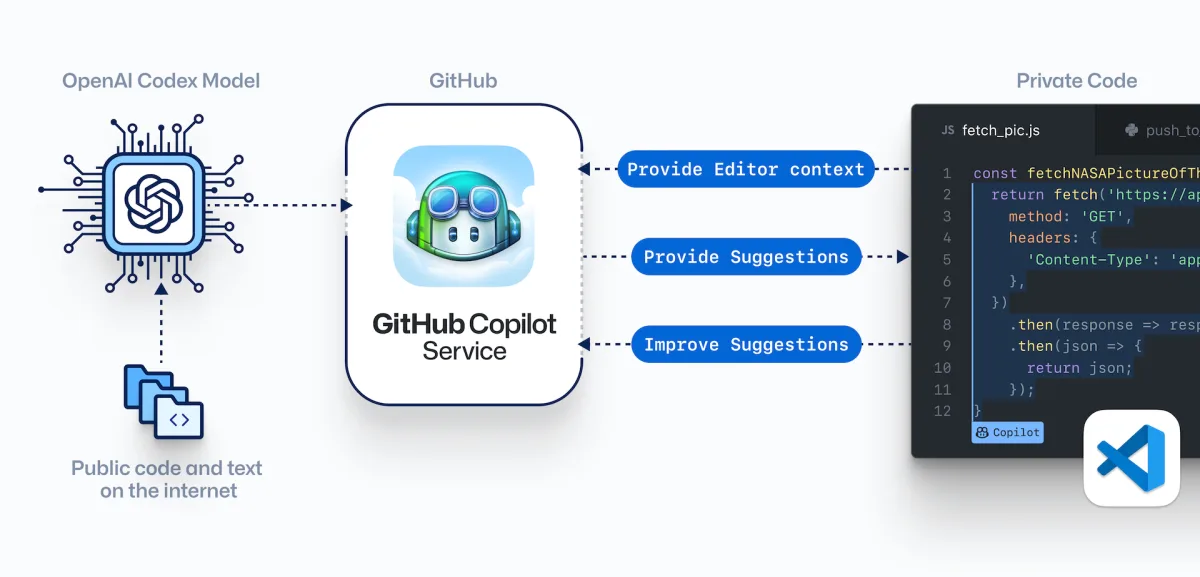
The features of Copilot are really impressive.
-
Recommendations can be made in the most popular programming languages, JavaScript, Python, Ruby and TypeScript.
-
The ability to convert comments to code by simply writing a comment describing the logic you want, and then let GitHub Copilot assemble the code for you.
-
Get suggestions for whole lines or entire functions right inside your IDE.
-
Quickly produce boilerplate and repetitive code patterns. Feed it a few examples and let it generate the rest of the code block.
-
Let copilot write your specs; the tool suggest tests that match your implementation code.
-
There are many different ways to write a single software function, the tool presents different solutions to achieve the same result.
All of this means that there are many questions that need to be answered before many will be comfortable using this tool.
-
Who owns the code that’s been generated by the AI? Does it belong to the developer or does it belong to GitHub (Microsoft).
-
What licence does the generated code fall under?
-
What projects were used to train this model, MIT, GPLv3, BSD, Apache 2.0? It’s mentioned that the repositories they trained the model on are public only. Public repositories have a variety of different licences.
-
Is there any possibility of proprietary code being generated in open source projects? Lawsuits like Google vs Oracle spring to mind.
GitHub are working hard to personify this service, to make it appear like it’s another developer working alongside you in a pair programming session. I can see the attractivness of the service, who wouldn’t want the ability to rapidly develop code, to type characters and have functions appear. Productivity gains for the masses.
Many of applications developed in the world today are really simple programs, variations of updating a form. A tool like this would allow any junior developer to become productive. I do worry that this could become just another crutch for new developers, a newer and fancy iteration on the concept of copying and pasting solutions from StackOverflow.com.
OpenAI have stated that they will release the model this summer for third-party developers to weave into their own applications. GPT-3 has led to a slew of new businesses using the model to become the ‘smarts’ behind their startup. There will certainly be new and exciting ways of manipulating this new model that even GitHub and OpenAI have yet to think of. I’m certain that lawyers have already written memos to engineering departments forbidding their use of the tool.
In the long term I firmly belive lawyers are going to have a field day. The first legal case cannot come soon enough and will be eagerly watched around the world to prove if this model can be used freely without worry.
It is always exciting to have new tools and techniques released that can improve the life of the ecosystem at large. To even contemplate building these models, it’s well outside the reach of any small business from a cost and data generation perspective. I do worry if GitHub have thought of the long term impact, could FOSS and private businesses abandon GitHub knowing that their publicly available code is being used for a financial benefit for likes of Microsoft, OpenAI and others. By using the data in such a manner seems to go against the heart of the concept of Open Source.
Please keep in mind that OpenAI has been pledged over 1 billion USD directly from Microsoft, and has the backing of the titans of the software world such as Elon Musk, Sam Altman and Peter Thiel. This is definitely a for profit play built on the backs of open source developers, developers who never had the option of opting out.
Andreesen Horowitz famously stated that ‘Software is Eating the World’, we should question if software is in fact cannibalistic?
Feel free to subscribe to my newsletter, chat to me on mastodon or follow my blog in your favourite RSS reader.